
Hadoop Stream Processing Utilities Kafka and Samza
Kafka and Samza are both open-source stream processing platforms developed by Apache Software Foundation.
What is stream processing?
Say we have a timeline and two continuous data incoming at the same time, such as sensor metrics of a Uber's (longitude, latitude) and customer's status of this ride.
We want to get some "insights" from these data.
Kafka is a distributed event streaming platform that is used for building real-time data pipelines and streaming applications. It is commonly used for collecting, storing, and processing large amounts of data in real-time.
Samza, on the other hand, is a stream processing framework that is built on top of Kafka. It provides a way to process data streams in real-time and is designed to handle high-volume and low-latency data processing. Samza allows developers to write custom processing logic using the Apache Kafka Streams API or the Apache Samza API.
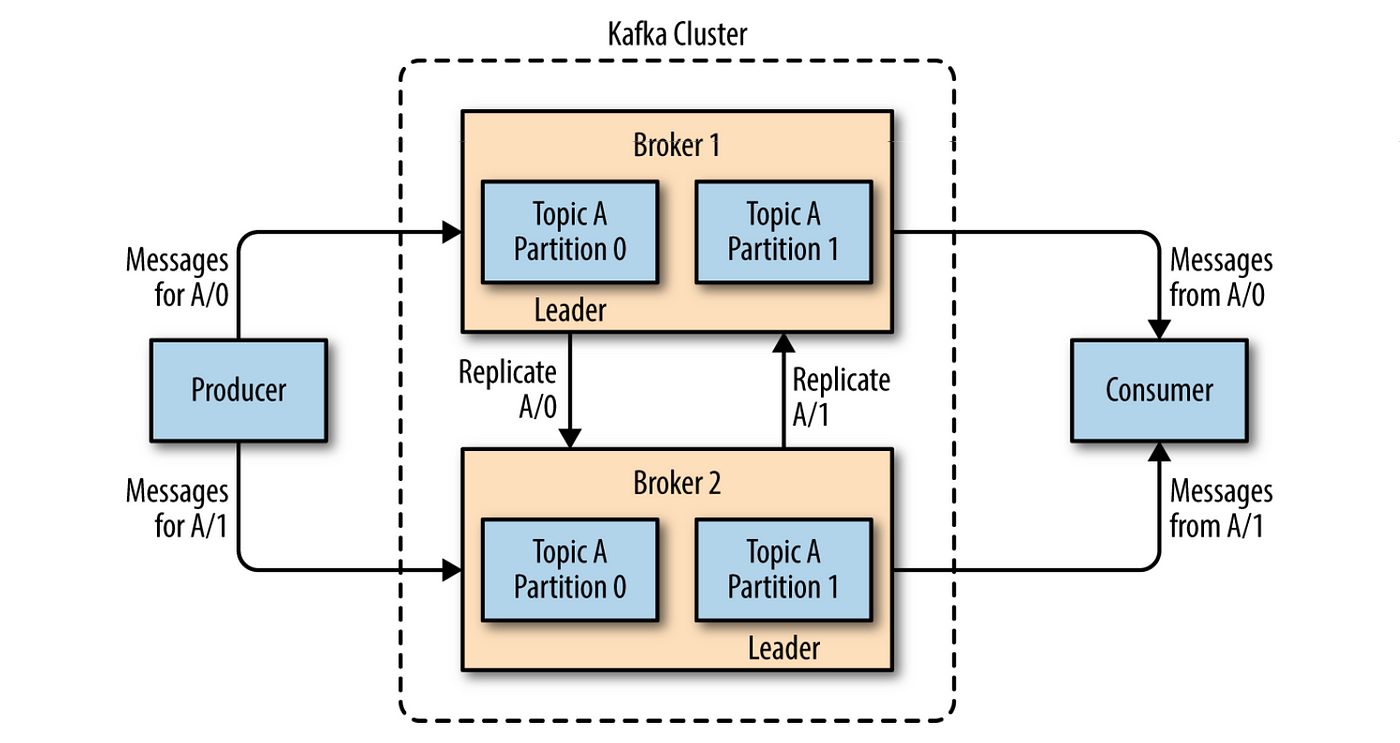
Kafka Producer
Terms
Topics: A category, i.e., driver-locations, events in this project.
Partitions: Within a Kafka topic, the data is partitioned into multiple partitions, which allow for horizontal scalability.
Topics allow data to be distributed across multiple partitions to enable scalability, parallel processing, and fault tolerance in Kafka.
Broker: Brokers are responsible for storing and serving data, handling client requests, and managing partitions and topics.
Each Kafka broker stores a portion of the data for one or more partitions of the topics that it is responsible for. Brokers communicate with each other to replicate data, balance the load, and ensure fault tolerance in the cluster.

Say we have following servers, get from Server Init Logs Outputs
log_uri = "s3n://aws-logs-stream-processing-24dd-us-east-1/"
master_public_dns = "ec2-54-160-17-173.compute-1.amazonaws.com"
workspace_public_dns = "ec2-54-145-170-197.compute-1.amazonaws.com"
Use the following broker IPs for bootstrap servers for submitting Task 1!
The IP of the master is: 172.31.4.0:9092
The IP list of Samza brokers in the cluster is given below for your reference.
172.31.14.9:9092,172.31.3.188:9092,172.31.4.0:9092
Kafka APIs & Commands (On Master Node, 172.31.4.0)
Create Topic
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic driver-locations --partitions 5 --replication-factor 1
kafka-topics.sh --bootstrap-server localhost:9092 --create --topic events --partitions 5 --replication-factor 1
Describe Topic
kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic driver-locations
[hadoop@ip-172-31-11-204 ~]$ kafka-topics.sh --bootstrap-server localhost:9092 --describe --topic driver-locations
Topic: driver-locations TopicId: ivzUNECfSACug-wrqrjkWQ PartitionCount: 5 ReplicationFactor: 1 Configs: segment.bytes=1073741824
Topic: driver-locations Partition: 0 Leader: 2 Replicas: 2 Isr: 2
Topic: driver-locations Partition: 1 Leader: 1 Replicas: 1 Isr: 1
Topic: driver-locations Partition: 2 Leader: 0 Replicas: 0 Isr: 0
Topic: driver-locations Partition: 3 Leader: 2 Replicas: 2 Isr: 2
Topic: driver-locations Partition: 4 Leader: 1 Replicas: 1 Isr: 1
Consume Data from a Topic
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic driver-locations --from-beginning
Delete Topic
kafka-topics.sh --bootstrap-server localhost:9092 --delete --topic driver-locations
Consume Message from a Topic
kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic <name of your topic> --from-beginning
Samza Consumer
Samza is designed to continuously compute data as it becomes available and provides sub-second response times
3-layers Architecture
- Execution Layer: YARN (Yet Another Resource Negotiator) is Hadoop’s cluster scheduler.
- Streaming Layer: Apache Kafka is used in this project as streaming layer.
- Processing Layer: After process + transformations, Samza produce output.
Samza Terms
Streams: equivalent to Kafka Topics
Jobs:
- Written using Samza API.
- Contains many tasks
- The number of task class instantiations equals the number of Kafka partitions
Stateful vs Stateless Samza Stream Proc.
Stateless: Filtering
Stateful: Using a remote data store (MySQL, slow) or in-memory store ( #Redis, faster but vulnerable to machine failures.) and retrieve state from the database in the Samza job.
Samza APIs
Most of the complexity of stream handling.
High Level Streams API:
- DAG of operations on message streams.
- i.e,
filtering, projection, repartitioning, joins, windows
Low Level Task API:
- Having specific processing for each data
- We are going to use this!
Sample code atsamza-hello-samzaproject on GitHub: https://github.com/apache/samza-hello-samza/blob/master/src/main/java/samza/examples/wikipedia/task/
Debugging Samza through YARN UI
https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-ssh-tunnel.html